
--------------------------------------------------------------------------------------------
N E W
F E A
T U R
E S
SQL 2000
· User Defined Functions
· Distributed Partitioned views
· Multiple SQL Server Instances
· Log shipping (only Enterprise Edition)
· Index Views
· Insert and After Trigger
· XML Support
· New Data types big int, sql variant.
· T-SQL enhancements
· CLR (Common Language Runtime)
· Service Broker
· Data Encryption
· SMTP mail
· HTTP end points
· MARS (Multiple Active Result Set)
· SQL Server Integration Service (SSIS)
· Database Mirroring
· Partition of Tables & Indexes
· Resource Database
ü Dynamic Management Views
ü
System Catalog Views
ü
Database Snapshots
ü
Support for Analysis Services on a a Failover Cluster.
ü
Profiler being able to trace the MDX queries of the Analysis
Server.
ü Peer-to Peer Replication
T-SQL enhancements:
Error handling vie TRY & CATCH Paradigm,
common table expression, ability to shift columns to rows and vice versa with
PIVOT & UNPIVOT Commands, High Performance data access.
CLR (Common Language Runtime):
Major enhancement is the integration of a .net
compliant language such as c#, asp.net or vb.net to built objects (sp,
triggers, and functions ext)
Service Broker:
Handles messaging between a sender and receiver in a loosely coupled
manner.
Data Encryption:
Have native capabilities to support encryption of data stored in user
defined databases.
SMTP mail:
Sending mail directly from SS 2000 is possible but challenging.
SS 2005 Microsoft Incorporate SMTP mail to improve the native mail
compatibilities.
HTTP end points:
You can easily create HTTP end point via T-SQL
MARS (Multiple Active Result Set):
.MAR's allow a persistent database connection
from a single client to have more than one active request per connection.
.The bottom line is that one client connection
can have multiple active processes simultaneously.
SQL Server Integration Service (SSIS):
SSIS has replaced DTS (Data Transformation
Service) as the primary ETL (Extraction Transformation and Loading) tools. Now
has a great deal of flexibility to address complex data movement.
Database Mirroring:
Partition of Tables & Indexes:
Partition of Tables & Indexes are supported natively
SQL 2008
·
Activity
Monitor
·
SQL Server
Audit
·
Backup
Compression
·
Table
compression
·
Extended
events
·
Policy-Based
Management
·
Enhanced
database mirroring
·
Transparent
Data Encryption (TDE)
·
Central
Management Servers
·
Multi server
Query Execution
·
Import and
evaluate policies across servers
·
Control
services and bring up SQL Server configuration Manager
·
Import and
Export the registered server's
·
Lock
Escalation
·
Instance Level
Granularity
·
Resource
Governor
Activity Monitor:
Use activity monitor to obtain information about
SQL Server processes and how these processes affect the current instance of SQL
Server.
The Activity
Monitor has following sections:
ü Overview:
Shows graphical displays of the percent of processor time, number of
waiting task's, database I/O and batch request(number per second).
ü Active User Task:
Shows information, for the active user connections to SQL Server
database Engine.
ü Resource Wait: Shows wait state information
ü Data File I/O: Shows I/O information for database data and log file.
ü Recent Expensive Queries:
Shows information about the most expensive
queries.
SQL Server Audit: Ability to audit at the server, database and
table levels.
Having the ability to monitor and log events,
such as who is accessing objects, what changes occurred and what time changes.
Can help the DBA to meet compliance standards for regulatory or organizational
security requirements.
Within SQL Server 2008 (enterprise and dev
edition only) SQL Server audit provides automation that allows the DBA and
others to enable, store and view audit on various server and database
components.
This feature allows at a granularity of the
server and database level.
Audit results can be sent to a file or event log.
Backup Compression:
Compressing a backup typically requires less
device I/O and therefore usually increases backup speed significantly.
in Lab tests conducted with real customer data,
we observed in many cases a reduction in the backup file size between 70% and
85% testing also revealed around a 45% reduction in the backup and restore
time.
Table Compression: Compress
data and index pages to save memory and I/O
Extended evens: Event collection is easier now compare to
running a trace
Policy-Based
Management: The ability to manage
standards on multiple servers.
Enhanced database
mirroring: Automatic data page repair
and compressing outgoing log stream.
Transparent Data
Encryption (TDE): Encrypt
database without code changes
Central Management
Servers:
It will allow the DBA to register a group of servers and apply
functionality to the server's, as a group such as:
Multi server Query
Execution:
A script can now be executed from one source,
across multiple SQL Servers and be returned to that source, without the need to
distinctly log into every server.
The syntax is supported in earlier server
versions. a query executed from the query editor in SQL server 2008 can run
against SS 2005 and SS 2000 instances as well.
Import and evaluate
policies across servers
As part of policy based management, SS 2008
provides the ability to import policy files into particular Central Management
Server Groups and allows policies to be evaluated across all of the servers
registered in the group.
Control services and bring up SQL Server configuration Manager
Import and Export the registered server's
Servers within the Central Management Server can
be exported and imported for use between DBA's or different SQL Server
Management Studio Instance Installation.
SQL 2008 R2
SQL Server 2008 R2 Datacenter supports 256 logical processors.
SQL Server Utility: Central repository control for multiple SQL Servers.
Multi Server Dashboards: Dashboards showing combined server data can
be created.
Master data services: To manage enterprise central database.
SSMS enhancements for SQL Azure: SSMS supports for cloud.
Licensing
Model: It’s
not based on sockets introduced new core based licensing model.
Edition
changes:
Introduced new BI edition and retired Datacenter, workgroup and standard for
small business.
Always
ON
Contained
Databases
User
Defined Server Roles
New
date and time functions
New
FORMAT and CONCAT functions
New
IIF and CHOOSE functions
New
paging features with OFFSET and FETCH
SQL Server 2014.
1. Standard edition
memory capability: increased to 128 GB whereas
2012 standard editions it is 64 GB.
2. SQL Server developer
edition is free: MS made SQL Server 2014
Developer edition license free
3. AlwaysOn Enhancements
Microsoft has enhanced AlwaysOn integration
by expanding the maximum number of secondary replicas from 4 to 8. Readable secondary
replicas are now also available for read workloads, even when the primary
replica is unavailable. In addition, SQL Server 2014 provides the new Add
Azure Replica Wizard, which helps you create asynchronous secondary replicas in
Windows Azure.
4. Backup Encryption
One welcome addition to SQL Server 2014 is
the ability to encrypt database backups for at-rest data protection. SQL Server
2014 supports several encryption algorithms, including Advanced Encryption
Standard (AES) 128, AES 192, AES 256, and Triple DES. You must use a
certificate or an asymmetric key to perform encryption for SQL Server 2014
backups.
5. SQL Server Managed
Backup to Windows Azure
SQL Server 2014’s native backup supports
Windows Azure integration. Although I’m not entirely convinced that I would
want to depend on an Internet connection to restore my backups, on-premises SQL
Server 2014 and Windows Azure virtual machine (VM) instances support backing up
to Windows Azure storage. The Windows Azure backup integration is also fully
built into SQL Server Management Studio (SSMS).
6. Buffer Pool Extension
SQL Server 2014 provides a new solid state disk
(SSD) integration capability that lets you use SSDs to expand the SQL Server
2014 Buffer Pool as nonvolatile RAM (NvRAM). With the new Buffer Pool
Extensions feature, you can use SSD drives to expand the buffer pool in systems
that have maxed out their memory. Buffer Pool Extensions can provide
performance gains for read-heavy OLTP workloads.
7. In-Memory OLTP Engine
SQL Server 2014 enables memory optimization
of selected tables and stored procedures. The In-Memory OLTP engine is designed
for high concurrency and uses a new optimistic concurrency control
mechanism to eliminate locking delays. Microsoft states that customers can
expect performance to be up to 20 times better than with SQL Server 2012 when
using this new feature. For more information, check out “Rev Up Application Performance with
the In-Memory OLTP Engine.”
8. Updateable Columnstore
Indexes
When Microsoft introduced the columnstore
index in SQL Server 2012, it provided improved performance for data warehousing
queries. For some queries, the columnstore indexes provided a tenfold
performance improvement. However, to utilize the columnstore index, the
underlying table had to be read-only. SQL Server 2014 eliminates this
restriction with the new updateable Columnstore Index. The SQL Server 2014
Columnstore Index must use all the columns in the table and can’t be combined
with other indexes.
9. Storage I/O control
The Resource Governor lets you limit the
amount of CPU and memory that a given workload can consume. SQL Server 2014
extends the reach of the Resource Governor to manage storage I/O usage as well.
The SQL Server 2014 Resource Governor can limit the physical I/Os issued for
user threads in a given resource pool.
10. Power View for
Multidimensional Models
Power View used to be limited to tabular
data. However, with SQL Server 2014, Power View can now be used with multidimensional
models (OLAP cubes) and can create a variety of data visualizations including
tables, matrices, bubble charts, and geographical maps. Power View
multidimensional models also support queries using Data Analysis Expressions
(DAX).
Power BI for Office 365 is a cloud-based
business intelligence (BI) solution that provides data navigation and
visualization capabilities. Power BI for Office 365 includes Power Query
(formerly code-named Data Explorer), Power Map (formerly code-named GeoFlow),
Power Pivot, and Power View. You can learn more about Power BI at Microsoft’s Power BI for Office 365
site.
12. SQL Server Data Tools
for Business Intelligence
The new SQL Server Data Tools for BI
(SSDT-BI) is used to create SQL Server Analysis Services (SSAS) models, SSRS
reports, and SSIS packages. The new SSDT-BI supports SSAS and SSRS for SQL
Server 2014 and earlier, but SSIS projects are limited to SQL Server 2014. In
the pre-release version of SQL Server 2014, SQL Server Setup doesn’t install
SSDT-BI. Instead, you must download SSDT-BI separately from the Microsoft
Download Center.
New
Features worth Exploring in SQL Server 2016
SQL Server Developer Edition is free: MS made SQL Server 2014
Developer edition free and same continued with SQL Server 2016 Developer
edition.
Always on Enhancements:
Standard Edition will come with AGs support with one database per group
synchronous or asynchronous, not readable.
3 sync replicas supported whereas it was 2 in SQL 2014. Listener will be able to do round-robin load
balancing of read-only requests on multiple secondaries. Now supports Microsoft DTC. SQL Server
AlwaysOn to Azure Virtual Machine.
TempDB Enhancements: Trace
flag 1117 and 1118 are not required for TEMPDB anymore. When TEMPDB is having database files all
files will grow at the same time based on growth settings. All allocations in TEMPDB will use uniform
extents. By default, setup adds as many TEMPDB files as the CPU count or 8,
whichever is lower. We can have the
control on TEMPDB configuration while installing SQL Server 2016.
Replication enhancements: Replication
supports memory-optimized tables and replication support enabled for Azure SQL
Database.
Always Encrypted: With the Always Encrypted feature enabled your SQL Server data will always be encrypted within SQL Server. Access to encrypted data will only be available to the applications calling SQL Server. Always Encrypted enables client application owners to control who gets access to see their applications confidential data. It does this by allowing the client application to be the one that has the encryption key. That encryption key is never passed to SQL Server. By doing this you can keep those nosey Database or Windows Administrators from poking around sensitive client application data In-Flight or At-Rest. This feature will now allow you to sleep at night knowing your confidential data stored in a cloud managed database is always encrypted and out of the eyes of your cloud provider.
Dynamic Data Masking: If you are interested in securing your confidential data so some people can see it, while other people get an obscured version of confidential data then you might be interested in dynamic data masking. With dynamic data masking you can obscure confidential columns of data in a table to SQL Server for users that are not authorized to see the all the data. With dynamic data masking you can identify how the data will be obscured. For instance say you accept credit card numbers and store them in a table, but you want to make sure your help desk staff is only able to see the last four digits of the credit card number. By setting up dynamic data masking you can define a masking rules so unauthorized logins can only read the last four digits of a credit card number, whereas authorized logins can see all of the credit card information.
JSON Support: JSON stands for Java Script Object Notation. With SQL Server 2016 you can now interchange JSON data between applications and the SQL Server database engine. By adding this support Microsoft has provided SQL Server the ability to parse JSON formatted data so it can be stored in a relation format. Additionally, with JSON support you can take relational data, and turn it into JSON formatted data. Microsoft has also added some new functions to provided support for querying JSON data stored in SQL Server. Having these additional JSON features built into SQL Server should make it easier for applications to exchange JSON data with SQL Server.
Multiple TempDB Database Files: It has been a best practice for a while to have more than one tempdb data file if you are running on a multi-core machine. In the past, up through SQL Server 2014, you always had to manually add the additional tempdb data files after you installed SQL Server. With SQL Server 2016 you can now configure the number of tempdb files you need while you are installing SQL Server. Having this new feature means you will no longer need to manually add additional tempdb files after installing SQL Server.
PolyBase: PolyBase allows you to query distributed data sets. With the introduction of PolyBase you will be able to use Transact SQL statements to query Hadoop, or SQL Azure blob storage. By using PolyBase you can now write adhoc queries to join relational data from SQL Server with semi-structured data stored in Hadoop, or SQL Azure blob storage. This allows you to get data from Hadoop without knowing the internals of Hadoop. Additionally you can leverage SQL Server’s on the fly column store indexing to optimize your queries against semi-structured data. As organizations spread data across many distributed locations, PolyBase will be a solution for them to leverage SQL Server technology to access their distributed semi-structured data.
Query Store: If you are into examining execution plans than you will like the new Query Store feature. Currently in versions of SQL Server prior to 2016 you can see existing execution plans by using dynamic management views (DMVs). But, the DMVs only allow you to see the plans that are actively in the plan cache. You can’t see any history for plans once they are rolled out of the plan cache. With the Query Store feature, SQL Server now saves historical execution plans. Not only that but it also saves the query statistics that go along with those historical plans. This is a great addition and will allow you to now track execution plans performance for your queries over time.
Row Level Security: With Row Level Security the SQL database
engine will be able to restrict access to row data, based on a SQL Server
login. Restricting rows will be done by filter predicates defined
in inline table value function. Security policies will ensure the filter
predicates get executed for every SELECT or DELETE operation.
Implementing row level security at the database layer means application
developers will no longer need to maintain code to restrict data from some
logins, while allowing other logins to access all the data. With this new
feature, when someone queries a tables that contains row level security they
will not even know whether or not any rows of data were filtered out.
R Comes to SQL Server; With Microsoft’s purchase of Revolution Analytics they are now able to incorporate R to support advance analytics against big data right inside of SQL Server. By incorporating R processing into SQL Server, data scientists will be able to take their existing R code and run it right inside the SQL Server database engine. This will eliminate the need to export your SQL server data in order to perform R processing against it. This new feature brings R processing closer to the data.
Stretch Database: The Stretch Database feature provides you a method to stretch the storage of your On-Premise database to Azure SQL Database. But having the stretch database feature allows you to have your most frequently accessed data stored On-Premise, while your less accessed data is off-site in an Azure SQL databases. When you enable a database to “stretch” the older data starts moving over to the Azure SQL database behind the scenes. When you need to run a query that might access active and historical information in a “stretched” database the database engine seamlessly queries both the On-Premise database as well as Azure SQL database and returns the results to you as if they had come from a single source. This feature will make it easy for DBA’s to archive information to a cheaper storage media without having to change any actual application code. By doing this you should be able to maximize performance on those active On-Premise queries.
Temporal Table: A temporal table is table that holds old versions of rows within a base table. By having temporal tables SQL Server can automatically manage moving old row versions to the temporal table every time a row in the base table is updated. The temporal table is physically a different table then the base table, but is linked to the base table. If you’ve been building or plan to build your own method to managing row versioning then you might want to check out the new temporal tables support in SQL server 2016 before you go forth and build your own row versioning solution.
New
in SQL Server 2017
1. SQL Server on Linux
SQL Server is not only Windows-based RDBMS even it can run on a different flavor of Linux operating systems. You can develop applications with SQL Server on Linux, Windows, Ubuntu, or Docker and deploy them as well on these platforms. SQL Server can now compete with other RDBMS like Oracle which is more popular on Linux.
SQL Server is not only Windows-based RDBMS even it can run on a different flavor of Linux operating systems. You can develop applications with SQL Server on Linux, Windows, Ubuntu, or Docker and deploy them as well on these platforms. SQL Server can now compete with other RDBMS like Oracle which is more popular on Linux.
2. Adaptive Query Processing
Adaptive Query Processing is the new feature introduced in SQL Server 2017. Adaptive Query Processing improvements adapts optimization strategies to your application workload’s runtime conditions. Cardinality estimation process helps to estimate the number of rows processed in execution plan at each and every step during optimization.
Adaptive Query Processing is the new feature introduced in SQL Server 2017. Adaptive Query Processing improvements adapts optimization strategies to your application workload’s runtime conditions. Cardinality estimation process helps to estimate the number of rows processed in execution plan at each and every step during optimization.
Sometimes, the query optimizer makes poor decisions regarding algorithm selection and order of operations. When estimates are inaccurate at that time we do not change our query plan execution strategy during execution.
3. Resumable Online Index Rebuild
Resumable Online Index Rebuild allows you to resume an online index rebuild operation from where it stopped after a failure like running out of disk space or database failure. It uses the small amount of log space to rebuild indexes. You can also pause and resume ongoing index rebuild operation. It also helps to avoid out-of-log errors.
Resumable Online Index Rebuild allows you to resume an online index rebuild operation from where it stopped after a failure like running out of disk space or database failure. It uses the small amount of log space to rebuild indexes. You can also pause and resume ongoing index rebuild operation. It also helps to avoid out-of-log errors.
SQL Server 2017 is the first commercial RDBMS to support pause and resume functionality for index maintenance operations. Most administrators consider index rebuild on VLDB’s a daunting task to manage. Many critical database solutions don’t permit to perform offline database maintenance operations. In most cases, the database design plays an important role in that regard. SQL Server 2017 provides index maintenance tasks with great flexibility as an alternative solution to managing the maintenance operations. There are situations where database administrators might need to temporarily free up system resources. For example, what if a priority task needs resources and a lower-priority index rebuild is eating away the resources? We’d rather have the index rebuild operation run in some other available maintenance window—but at the same time, what if the rebuild was halfway? We do not want to lose that state either. In such a case, the operation can be paused, and resumed during a maintenance window. This can be a termed as “piecemeal index maintenance operation.”
- Resume: Resume an index-rebuild operation, after a failure.
- Pause: Pause the rebuild operation (and resume it at a later point).
- Rebuild: Rebuild large indexes with minimal log space usage.
Here is an outline of the SQL 2017 Resumable Index Rebuild features and other considerations.
- Better planning and a greater flexibility in the management of indexes during maintenance windows. Provides an option to pause and restart an index rebuild operation multiple times.
- Flexibility to recover from index rebuild failures, since the process does not necessarily have to start from the beginning.
- Space can be a game-changer (storage constraint), when an index operation is paused—both, the original index and the newly created one require disk space.
- Better log space management since it enables truncation of transaction logs during an index rebuild operation.
- SORT_IN_TEMPDB=ON is not supported.
-- Syntax for SQL Server and SQL Database
ALTER INDEX { index_name | ALL } ON <object>
{
REBUILD {
[ PARTITION = ALL ] [ WITH ( <rebuild_index_option> [ ,...n ] ) ]
| [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> ) [ ,...n ] ]
}
| RESUME [WITH (<resumable_index_options>,[…n])]
| PAUSE
| ABORT
}
[ ; ]
<rebuild_index_option > ::=
{
| ONLINE = {
ON [ ( <low_priority_lock_wait> ) ]
| OFF }
| RESUMABLE = { ON | OFF }
| MAX_DURATION = <time> [MINUTES}
}
<resumable_index_option> ::=
{
MAXDOP = max_degree_of_parallelism
| MAX_DURATION =<time> [MINUTES]
| <low_priority_lock_wait>
}
Limitations
- The SORT_IN_TEMPDB=ON option is not supported
- Resumable index operations are not supported on disabled index
- Columnstore index is not supported
ALTER INDEX PK_ftb_Material_Issue on ftb_Material_Issue REBUILD WITH (ONLINE=ON, MAXDOP=1, RESUMABLE=ON) ;
4. Automatic Database Tuning
Automatic tuning is a database feature which helps to fix identified problems automatically by recommend solutions. In SQL server Automatic tuning notifies you if an unrealized performance issue detected. It helps you to take the preventive measure and corrections even its database engine automatically fixes the performance problems.
Automatic tuning is a database feature which helps to fix identified problems automatically by recommend solutions. In SQL server Automatic tuning notifies you if an unrealized performance issue detected. It helps you to take the preventive measure and corrections even its database engine automatically fixes the performance problems.
Monitoring the databases for optimal query performance, creating and maintaining required indexes, and dropping rarely-used, unused, or expensive indexes is a common database administration task. SQL Server 2017 can now assist database administrators in performing these routine operations by identifying problematic query execution plans and fixing SQL plan performance problems. Automatic tuning begins with continuously monitoring the database, and learning about the workload that it serves. Automatic database tuning is based on Artificial Intelligence; AI is now providing great flexibility in managing and tuning the performance of database systems. More on this topic is discussed in a dedicated post on automatic database tuning
5. Graph Database Capabilities
SQL Server introduced new feature Graph Database Capabilities to model many-to-many relationships. Using SQL Server as the foundational database management system, the graph relationships are integrated into Transact-SQL.
SQL Server introduced new feature Graph Database Capabilities to model many-to-many relationships. Using SQL Server as the foundational database management system, the graph relationships are integrated into Transact-SQL.
6. Clusterless Availability Groups
Using this feature we can configure AOAG\Alwayson Availability Group without windows cluster in SQL Server 2017. Now if you want to configure AOAG between windows and Linux based SQL Servers, you don’t need a windows cluster in place.
Using this feature we can configure AOAG\Alwayson Availability Group without windows cluster in SQL Server 2017. Now if you want to configure AOAG between windows and Linux based SQL Servers, you don’t need a windows cluster in place.
7. Cross-OS AOAG
Microsoft has given an option for clusterless AOAG, using which we can configure AOAG between windows based SQL Server and Linux based SQL Server, which helps you enable cross-OS migrations and testing.
Microsoft has given an option for clusterless AOAG, using which we can configure AOAG between windows based SQL Server and Linux based SQL Server, which helps you enable cross-OS migrations and testing.
8. New Functions
In SQL Server 2017 few new functions are also added. Below is the list of those new functions:
In SQL Server 2017 few new functions are also added. Below is the list of those new functions:
9. New DMVs(Dynamic Management Views)
SQL Server 2017 also has few new DMV introduced. Below is the list of those new DMVs.
SQL Server 2017 also has few new DMV introduced. Below is the list of those new DMVs.
- sys.dm_tran_version_store_space_usage
- sys.dm_db_stats_histogram
- sys.dm_exec_query_statistics_xml
- sys.dm_os_host_info
- sys.dm_db_file_space_usage
10. New DMFs(Dynamic Management Functions)
With all these, SQL Server 2017 has few new DMFs also added to it. Below is the list of those new DMFs.
With all these, SQL Server 2017 has few new DMFs also added to it. Below is the list of those new DMFs.
- sys.dm_db_log_info
- sys.dm_db_log_stats
Python support in ML (Machine Learning)
The next great feature that’s new in SQL Server 2017
is the addition of support for the Python scripting language, which
is in addition to R, support for which was added in 2016, to form a new
machine-learning services package. There’s no doubt that AI is now among the
hottest buzzwords in IT. It seems like almost every IT product is now suddenly
AI-enabled, and SQL Server is no exception in that regard. In April 2017, SQL
Server was officially touted as “The first RDBMS with built-in AI!”
String functions
One of the major capabilities of modern computers is
processing the human language. Basically, the strings are transformed into the
code which is then processed by a machine. The built-in string functions have
always been efficient in handling string literals. It is possible to find and
alter string values using various options. However, string functions and string
manipulation consume most of the query execution time in decoding the various
parts of the character literals. SQL Server 2017 offers various new string
manipulation functions, which have been in the talk for many of its features
that simplify a developer’s life; no more writing long T-SQL statements with
temporary tables and complex logic, only to manipulate and aggregate strings.
Here are some of the new string manipulation functions present
in SQL Server 2017:
DMVs and DMFs
With the advent of system objects, the metadata of
various pieces of SQL Server have been exposed for a better understanding of
the entire system. These system objects, for the most part, are a cumulative
collection of data, or the aggregation or accumulation of the various counter
values or different data-structures of SQL Server. Most importantly, the data
is real time, and obviously dynamic in nature. In most of the cases, the DMVs
are used, and they define the baseline or pressure points of various metrics
that determine the performance of the system. The DMFs provide cumulative statistics
of the requested parameters.
The new DMVs introduced in SQL Server 2017 are as follows:
- sys.dm_tran_version_store_space_usage
- sys.dm_db_stats_histogram
(Transact-SQL)
- sys.dm_exec_query_statistics_xml
- sys.dm_os_host_info
- sys.dm_os_sys_info
- A new column modified_extent_page_count introduced
in sys.dm_db_file_space_usage to
track differential changes in each database file of the database.
- Identify the free disk space using the new DMV sys.dm_os_enumerate_fixed_drives
Cross database transactions are now
supported among all databases that are part of an Always On Availability
Group, including databases that are part of same instance. See Transactions
- Always On Availability Groups and Database Mirroring (CTP 2.0)
Microsoft SQL Server 2017 Vs. 2019
SQL Server 2019 New Features-
Big Data Clusters
The latest version of SQL Server simplifies big data analytics for users. It combines Apache Spark and HDFS (Hadoop Distributed Filing System) and provides one integrated system. The new SQL server allows you to build “Big Data Clusters” using a blend of SQL Server and Apache Spark containers over Kubernetes utilizing SQL Server’s current PolyBase features. With the help of local Kubernetes, which is supported by public clouds, you’ll be able to deploy Big Data Clusters on AWS, on Azure, on GCP, and also on your own infrastructure.
Always On Availability Groups
For the first time, Always On Availability Groups were introduced in SQL Server 2012. Since then, Microsoft has made some improvements to this feature in each new release. In the same way, in SQL Server 2019, has made improvements to the high availability and disaster recovery feature. In the new version, the Always On Availability Group can have 5 synchronous replicas (1 primary copy and 4 secondary ones) for failover purposes, whereas there were 3 limitations in previous SQL Server 2017.
One of the great things about this feature is that it enables numerous duplicates of a database to be reproduced on different servers. SQL Server 2019 can redirect connections for customer applications from a secondary replica to the primary one. This means that a customer can be redirected to the primary replica without using the accessibility group listener, which is a virtual system name used to interface customers to databases in replicas.
UTF-8 Support
This feature provides significant storage savings. The new version supports the widely used UTF-8 encoding as an export or import encoding, or column-level or as a database-level grouping for text data. Thus, Unicode string data will take up much less storage space than the previous UTF-16.
UTF-8 is permitted in VARCHAR and CHAR and extends capabilities when creating or changing an object’s collation with UTF-8. And you can use the familiar CHAR data type rather than NCHAR, as CHAR requires only 10 bytes, whereas NCHAR requires 20 bytes for the same Unicode string data storage.
Resumable online index
The most exciting capabilities are related to indexing. Probably many database administrators face a terrible situation when an indexing operation goes wrong. Finally, SQL Server 2019 has come up with the new features to cope with these situations. When resumable online index is created, we can pause the indexing process and then resume from where we left off. We don’t need to start again from the very beginning.
New SQL Server 2019 supports the recovery of indexing failure. The process may fail due to many factors, such as after running out of disk space or after a database failure. You can resume the indexing process, once you have corrected the error that caused the index operation to crash without having to start over.
New SQL Server 2019 also reduces the amount of log space required when you create a large index, compared to the previous SQL Server 2017.
Additionally, SQL Server 2019 has a new feature for online conversion of conventional row storage tables to columnstore indexes. In the previous SQL Server 2017, such conversions could only be performed offline. But, with the latest version of SQL Server 2019 and Azure SQL Database, we can create or re-create Creating clustered columnstore indexes (CCI) online.
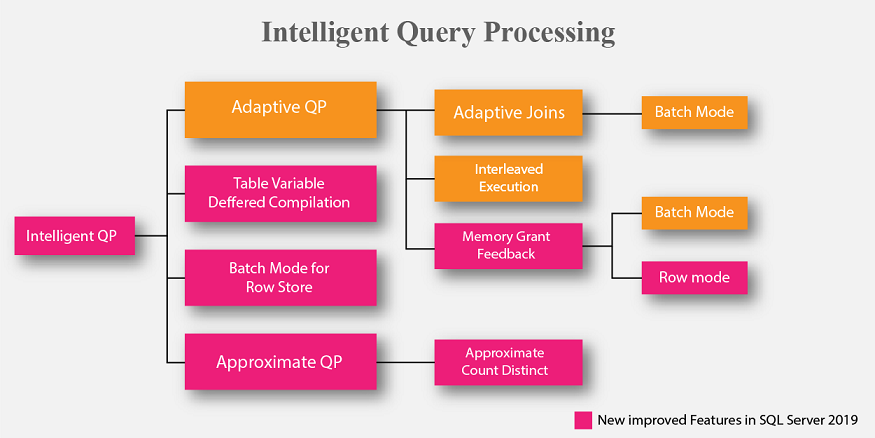
Intelligent Query Processing
The new Intelligent Query Processing suite is developed to fix some of the common query execution issues by adopting some automatic corrective strategies at runtime. It uses feedback data insights gathered from past executions. Microsoft has also started leveraging some of these features in Azure SQL DB and plans to keep expanding this region for SQL Server 2019. The image above shows the new and improved areas in the Intelligent Query Processing features.
Added features for SQL Server on Linux
Microsoft has added plenty of new features to its Linux edition. Perhaps the most exciting update is support for data replication which enables you to build distributed SQL databases effectively, especially those related to the Linux version of the Distributed Transaction Coordinator.
Another significant expansion of the Linux version is the ability to set up Always On Availability Groups in Docker containers arranged with Kubernetes. Additionally, for Linux, Microsoft makes certified container images available and places all of its windows and container images for SQL Server 2019 and SQL Server 2017 into the Microsoft Container Registry.
Another significant added feature – SQL Server 2019 on Linux supports OpenLDAP. It is an open source form of the Lightweight Directory Access Protocol. Although OpenLDAP can work autonomously of Microsoft’s Active Directory, the new support for OpenLDAP allows Linux-based SQL Server databases to join Active Directory.
In addition, another important part of SQL Server 2019, Microsoft has included integrated tools for building and testing machine-learning models on Linux. Thus, it enables SQL Server on Linux users to run machine learning applications written in Python and R languages.
Master Data Services (MDS)
Silverlight controls are replaced with HTML: Silverlight support for MDS portal is no longer needed. HTML controls will now perform the same function.
Security
The new version has come up with advanced security support. It encrypts the data using secure enclave technology. Certificate management is now integrated into the SQL Server Configuration Manager. A widely used SSL/TLS certificates are integrated to secure access to SQL Server instances.
Finally, in this article, I have mentioned some of the improved features in the new version of SQL Server 2019. However, there are some significant improvements coming to the often used functional areas in SQL Server. You can find other areas that will be useful in your SQL Server environment. The preview version is now available for Windows, Linux, and Docker. All you need to do is download it and see what it can do for you.
Microsoft SQL Server 2017 Vs. 2019
Below are few distinctive features that differentiate the SQL
Server 2017 version from SQL Server 2019.
Topics
|
SQL Server 2017
|
SQL Server 2019
|
Big Data clusters
|
Was not included
|
New feature of big data cluster incorporated to handle the
big data problems
|
Security
|
Always Encrypted” feature encodes data. Encoded data
cannot handle any mathematical or relational operations on them.
|
“Secure Enclaves” improvises over the previously encoded
data by allowing the basic mathematical or relational operations on encoded
data.
|
Intelligent Query Processing
|
Adaptive Joins in batch mode and memory feedback in batch
mode supported.
|
Along with previous version features, includes memory
feedback in row store mode and Scalar UDF Inlining.
|
Indexes
|
Resumable Online Index Rebuilding
|
Resumable Online Index Create
|
Always On availability groups
|
2 replicas
|
5 replicas
Secondary to primary index replica
redirection
|
Linux
|
Doesn’t support the openLDAP
|
Supports OpenLDAP
|




SQL Server 2019 New Features


ReplyDeleteThank you for sharing very useful blog!!!!
Azure DevOps online training
Microsoft Azure DevOps Online Training
Good Informatic Blog!!!
ReplyDeleteAzure SQL Training
SQL Azure Training
SQL Azure Online Training